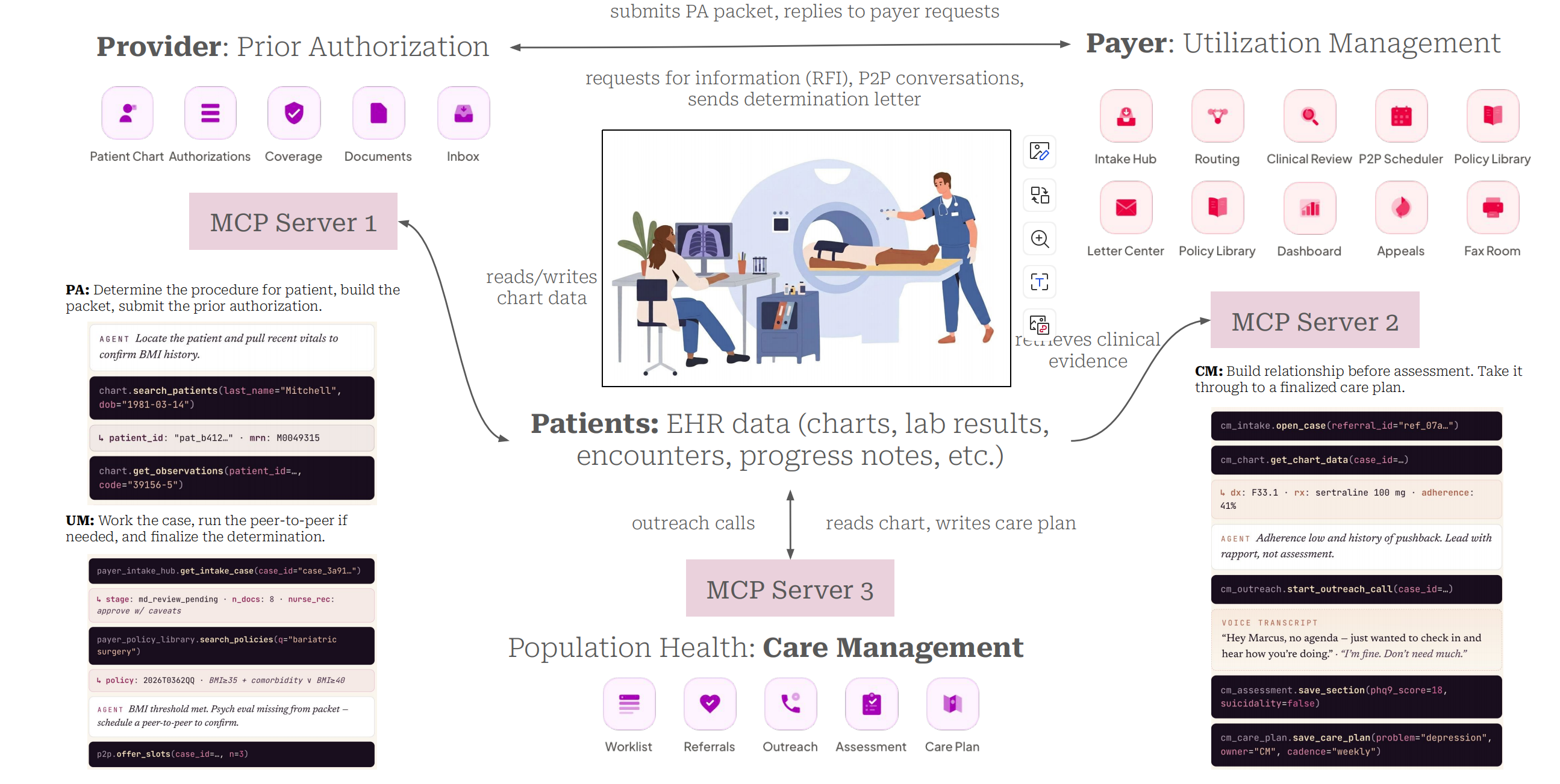
Open-source CHI-Bench from actAVA.ai puts 30 frontier agents through 75 long-horizon prior authorization, utilization review, and care management workflows.
SAN FRANCISCO, CA, UNITED STATES, May 20, 2026 /EINPresswire.com/ — AI company actAVA.ai today released CHI-Bench, the world’s first long-horizon healthcare benchmark for AI agents. Across 75 workflows and 30 frontier agents from Anthropic, OpenAI, Google, x.AI, DeepSeek, and Z.ai, the best-performing agent fails roughly seven out of ten real clinical cases. Code, data, and the live leaderboard are at actava.ai/benchmarks.
AI labs position agents as ready for long workflows, but until now no public benchmark validated that claim in healthcare, where one missed policy check can mean a denied authorization, delayed treatment, or audit finding. Each trial in CHI-Bench runs an agent for 60-80 steps across four to six clinical stages, exposing 21 healthcare apps through 200+ MCP tools and a 1,279-document operations handbook. It evaluates the trajectory, every artifact, and world state using deterministic unit tests and LLM judge for evidence grounding, consent, and cross-stage consistency.
Across the 30 frontier agents tested, Anthropic’s Claude Code with Opus 4.6 achieved the best overall performance at 28% pass@1, followed by OpenAI’s Codex with GPT-5.5 at 21%. By domain, utilization review reached 41%, care management 32%, and prior-authorization paperwork 29%. Reliability remained a major issue, with no agent clearing 20% when the same case was run three times. Under endurance testing, where agents were asked to handle 25 cases in one session, the best system completed under 4%. In a fully end-to-end setting, where one AI submitted a prior-auth request and a second acted as the UM reviewer, no task passed successfully.
CHI-Bench was built with a 20+ institution coalition spanning health systems (Johns Hopkins, Wellstar, Yale) and universities (Stanford, CMU, Oxford, USC, UCSD), with world-class AI researchers Caiming Xiong (Recursive Superintelligence), Sanmi Koyejo (Stanford), Eric P. Xing (CMU; MBZUAI), and Philip S. Yu (UIC).
“These workflows are long, role-composed, and gated by policy,” said Haolin Chen, lead author. “An agent has to play intake clerk, nurse reviewer, and medical director across sixty-plus steps where one wrong site-of-service flip cascades into multiple failures.”
“We need to know whether an agent can carry a real case end-to-end without error,” said Weiran Yao, Chief AI Officer of actAVA. “CHI-Bench is built for that.”
CHI-Bench is open under Apache 2.0 on GitHub; the leaderboard accepts community submissions today.
About actAVA.ai
actAVA.ai is a specialized AI platform that standardizes and accelerates the creation, training, and deployment of artificial intelligence solutions for healthcare and life sciences. We are a high-speed assembly line that automates the build and deployment of highly tested, always compliant, ever-learning agentic AI. actAVA is the Healthcare AI factory.
Media Contact: research@actava.ai
Follow: LinkedIn /company/actava · X @actAVAai
Shunxin Pang
HashMatrix
+1 416-605-0175
email us here
Legal Disclaimer:
EIN Presswire provides this news content “as is” without warranty of any kind. We do not accept any responsibility or liability
for the accuracy, content, images, videos, licenses, completeness, legality, or reliability of the information contained in this
article. If you have any complaints or copyright issues related to this article, kindly contact the author above.
![]()
Media gallery